
We’re knee-deep in data across all industries – healthcare, finance, education, government, you name it. We scan, digitize, and index records at breakneck speeds. Yet, poorly scanned PDFs create annoying speed bumps on this superhighway.
Converting these murky, skew-whiff, and sometimes barely legible documents into usable data can feel like trying to turn lead into gold.
Data extraction from scanned documents is like translating a foreign language- a language machines can understand. The translator leading this charge? Optical Character Recognition (OCR). OCR’s job is to spot printed characters on physical pages and turn them into electronic text – a format our systems can effortlessly process, index, and search.
However, when it comes to poorly scanned PDFs, the ability of OCR technology to accurately recognize these characters is significantly hampered. Poor-quality scans suffer due to low resolution, inconsistent lighting, skewed alignment, presence of noise (like spots or smudges), or the physical condition of the original document (such as old, faded, or crumpled papers).

OCR was originally intended for reading black text against a white background often using a flatbed scanner — not for extracting key data fields from ID documents using small fonts and different colored backgrounds that may include holograms, watermarks and printing on glossy surfaces³. The text recognition and extraction quality directly depend on the image input quality fed to the engine. For instance, the accuracy drops drastically when the character height is below 20 pixels⁴.
The Magnitude of the Problem
Each incorrectly interpreted word or missed line of text due to poor scan quality will slow down critical business processes, inflate operational costs, and risk serious errors. And, traditional OCR technologies only take us so far.
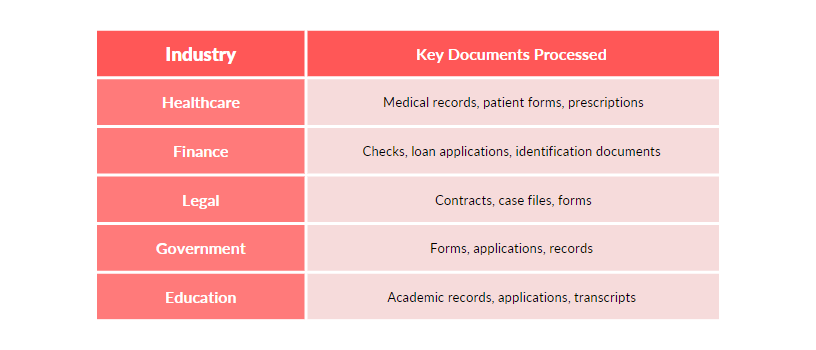
When OCR is Not Enough: The Need for AI
Correcting these OCR errors manually is not only time-consuming and expensive, but it also nullifies the main benefits of digitization – speed, accuracy, and automation. Hence, it’s crucial to find a more robust solution that can handle poorly scanned PDFs effectively, which is where advanced technologies like AI come into play.
AI brings to the table advanced machine learning and deep learning techniques that can tackle the issues traditional OCR stumbles upon.
How AI Helps in Extracting Data from Poorly Scanned PDFs
AI algorithms are robust enough to recognize patterns even in low-quality images and complex layouts. They learn from a vast array of samples and can generalize that learning to new, unseen documents. Additionally, AI’s contextual understanding vastly improves accuracy, catching errors that might slip past traditional OCR.
For instance, consider a poorly scanned invoice. An AI model could recognize patterns and layouts common to invoices, discern the likely position of essential fields like date, items, and total, and even correct potential errors based on learned context.
This level of accuracy can significantly reduce errors in accounting processes and contribute to more reliable financial reporting.
AI vs. OCR: A Comparative Analysis
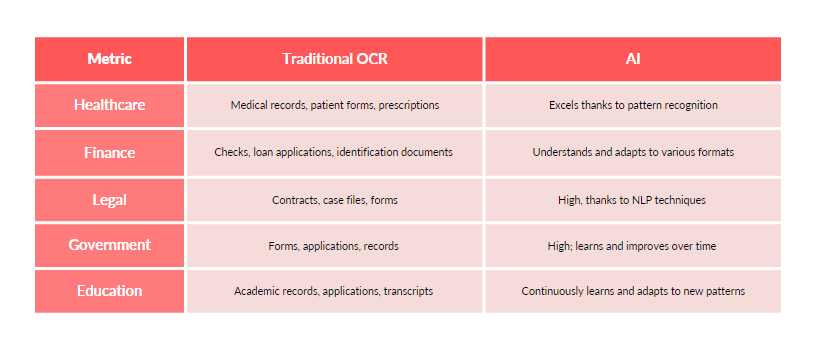
It’s clear that while OCR laid the groundwork, AI will enable the best in document data extraction.
It’s time to step into the future. Navigating the maze of poorly scanned PDFs with OCR has gotten us so far, but it’s clear that we’re ready for a more advanced solution.
With AI, you’re not just improving the accuracy of your data extraction. You’re empowering your team to work more efficiently, reducing costly errors, and ensuring that your organization stays ahead of the curve. Remember, in functions like accounting, even a small error can lead to significant discrepancies. AI brings to the table a level of precision, adaptability, and scalability that traditional OCR solutions can’t match.
If you’re curious about what AI can do for your organization, it’s time to see it in action. Discover firsthand how AI can transform your data extraction process, turning poorly scanned PDFs from frustrating obstacles into manageable tasks.
You’ve seen what OCR can do; now let’s see how much further AI can take us. Download this Case study to know more.


